Programming - Tumblr Posts - Page 5
Hey so, Type Families and Propositional Type Equality in Haskell are pretty cool even if I mostly used them as hacks for Haskell not having dependent typing.
First time I've heavily used Data.Type.Equality.
Rewriting proofs with `trans` is significantly more tedious in compound types and results in quite a few functions to help guide the types.
Overall pretty fun experience. Lack of `rewrite` really does ruin a lot of the satisfaction though.
(I also made it into a Kata)



Day 5 of learning Lean
why is proving ¬(p ↔ ¬p) so hard
Of course with Truth tables and classical logic, this is near trivial to solve. In fact here's the proof
example : ¬(p ↔ ¬p) := Not.intro λ(Iff.intro pnp npp) => have hnp : ¬p := (imp_iff_not_or.mp pnp).elim id id have hp : p := npp hnp hnp.elim hp
Could be a lot shorter, especially at proving the (¬p ∨ ¬p) part. But you get the gist.
Unfortunately this line exists

imp_iff_not_or is apparently only in classical logic, because it relies on the law of excluded middle which is (p ∨ ¬p) which intuitionistic logic does not have as ¬p is defined as (p -> False).
right now I'm looking into modal logic for solutions and it seems promising, having translations from Intuitional to KT4 modal logic, though I still don't know how I could translate it to a lean solution. It's also very likely there is a simpler solution that I am not seeing.
Either way, it's pretty fun despite my frustrations.
So far still stuck at page 3 of theorem proving in lean 4, though I only have 1 problem to solve.
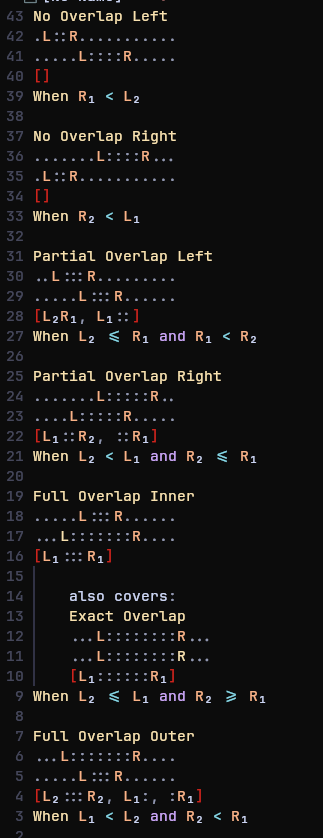
I really cannot keep track of ranges. Whether it's inclusive or exclusive, if ranges overlaps, and off-by-1 errors galore. I wrote this to keep track of a function. This is correct, atleast I hope so. Unrelated but I love the cmp-latex-symbols plugin.
Stuff like these are what makes me both love and hate Haskell

Complaints about syntax are almost always the dumbest criticisms I've heard about programming languages. It's almost always because of unfamiliarity. I don't know any sane language syntax that is such an issue after about 2 days of usage, if you're already familiar with the style beforehand.
The problem with C-Style is it's become what most people think about what programming languages look like. So whatever is a different style or even just deviates from C-Style is unfairly viewed as alien and esoteric.
Makes me wonder about the kinds of criticism C-Style would have if Lisp or ML-Syntax were most popular options
I'm a big fan of wizards-as-programmers, but I think it's so much better when you lean into programming tropes.
A spell the wizard uses to light the group's campfire has an error somewhere in its depths, and sometimes it doesn't work at all. The wizard spends a lot of his time trying to track down the exact conditions that cause the failure.
The wizard is attempting to create a new spell that marries two older spells together, but while they were both written within the context of Zephyrus the Starweaver's foundational work, they each used a slightly different version, and untangling the collisions make a short project take months of work.
The wizard has grown too comfortable reusing old spells, and in particular, his teleportation spell keeps finding its components rearranged and remixed, its parts copied into a dozen different places in the spellbook. This is overall not actually a problem per se, but the party's rogue grows a bit concerned when the wizard's "drying spell" seems to just be a special case of teleportation where you teleport five feet to the left and leave the wetness behind.
A wizard is constantly fiddling with his spells, making minor tweaks and changes, getting them easier to cast, with better effects, adding bells and whistles. The "shelter for the night" spell includes a tea kettle that brings itself to a boil at dawn, which the wizard is inordinately pleased with. He reports on efficiency improvements to the indifference of anyone listening.
A different wizard immediately forgets all details of his spells after he's written them. He could not begin to tell you how any of it works, at least not without sitting down for a few hours or days to figure out how he set things up. The point is that it works, and once it does, the wizard can safely stop thinking about it.
Wizards enjoy each other's company, but you must be circumspect about spellwork. Having another wizard look through your spellbook makes you aware of every minor flaw, and you might not be able to answer questions about why a spell was written in a certain way, if you remember at all.
Wizards all have their own preferences as far as which scripts they write in, the formatting of their spellbook, its dimensions and material quality, and of course which famous wizards they've taken the most foundational knowledge from. The enlightened view is that all approaches have their strengths and weaknesses, but this has never stopped anyone from getting into a protracted argument.
Sometimes a wizard will sit down with an ancient tome attempting to find answers to a complicated problem, and finally find someone from across time who was trying to do the same thing, only for the final note to be "nevermind, fixed it".
"If it looks stupid but it works, it ain't stupid" Me: "Hold my beer"
Teaching programming
One of the things I want to do is teach. My plan is, now that I (F'''ucking FINALLY!) finished my engineering degree, is to work a few years in the robotics industry, and then spend half my worktime there, and half teaching kids programming and code. Because,
A:
I feel that in the same way that you need to know physics, reading, internet literacy, history and a bunch of other skills to navigate the modern world, you also need programming. Not that everyone should become a software engineer. But everyone should be able to set up a few scripts to automate things on their PC, and know enough about how code works to know how the software that runs the world works. In the same way that you know enough about physics to know how satellites giving you internet works. Could you build that? No, of course not. Nor should you. But you know things can go in orbit. That things can communicate wirelessly over long distances and so on. You know enough about mechanics to use a screwdriver to take simple things apart and clean them, and know that you do NOT know enough to fix the electronics in your dishwasher.
You know it is not magic. Yet... programming is often thought of as that. And it really should not be. I swear to you. It is easy. Not to develop code to run a car, but to have it automatically edit text in a file according to rules you made? You betcha. B:
While learning to program as a job takes years, learning enough to understand the basics, and being able and unafraid to set up a script or throw together a python program to automatically sort files on your work computer really does not take a lot of time or effort. And I will guarantee, most students will benefit a lot from it. C:
Programming is much more a craft, like mechanic or carpenter. But more appealing for kids who are not confident in working with their hands. There is also good reasons for why it used to be thought of as a thing people who did not get along with others did. It is, in essence, defining and solving puzzles. To solve problems, that you also have to define yourself. Many a child have found that programming was a thing they could do, and be good at. A thing that helped them be confident. Maker spaces and learning programs with robotics or game development is filled with youngsters eager to learn. Who have finally find a thing they can be good at! But these programs a rare. And often schools and teachers mismanage how to run them. Not out of malice (There are few professions that is filled with more kindhearted people that deserves our endless appreciation than teachers), but because there are endless well paid and prestigious career opportunities for software developers. And so most schools will not have anyone who can even advice them when they set up these things. There is so much good to do. And I want to do some of it!
Frustrations
Following other developers, learners and makers are great. It facilitates learning and gives inspiration
But one thing that is often missing from people telling about how it is going, is the failures, frustrations and problems any developer will run into.
For this reason, two of my favorite maker youtube channels are Extractions&Ire (Chemistry) and Code Bullet (machine learning). Because these madlads are brave enough to not just show their process and result, but also their failures, mistakes and errors. And how they overcome them. Not always by learning (Sometimes making a dumb mistake is not really something you can learn from...)
It's good, because it's real.
Code tutorials and guides can give the impression that the normal process of development is "Open IDE, code, fix tiny typo error, compile, success". They don't do it out of malice, but out of a want to be concise. Which is fair.
So I also want to share when things do not go so well. I have programmed Atmel's AVR Chips for quite a while now. But I have done it mostly in microchip studio(former Atmel studio) and a bit in the arduino IDE. A job I am currently applying for, uses visual studio code. Which is fair enough. So to prepare for this specific job, and to acquire this quite good-to-have skill, I want to set that up for myself First things first, since I have not done this before, I cannot know if my code would have a weird error so I want to know everything else is working first. So I write a tiny program which simply have the microcontroller increase a number every 2 seconds and write it to my PC over UART. Takes 2 minutes.... I grab one of my Arduino Nano boards and a USB cable for it. And then... I cannot flash it... Its communication protocol have troubles.
I have seen this before. It is to do with the cables not being correct. If they are USB 2.0, very little magnetic noise can cause trouble. (And you cannot tell if a cable runs USB 2.0 or 3.0 by looking at it... because the universal serial bus is not universal... Insert grump rant here) I then spend an hour finding and trying different USB A to USB B-mini cables. Give up, notes down to buy (and MARK) some USB 3.0 versions for the future. I then grab a Arduino Uni instead, as they use USB B, which is much more resistant to noise... And then spend half an hour trying to find a the cable, as I do not have a lot of them, since... nearly nothing uses them. Finally find it, and yes, the program can now be flashed. So I packed all the cables I tested back in their places, after marking them so I will(hoefully) not have to do this again. Had to take several breaks feeling depressed and grumpy, and all in all, this adventure took 4-5 hours. And now I can START on this... And this is how work sometimes is. And that is ok. It is still... VERY frustrating ...
What do you think GIT stands for?
So fun fact about GIT
(For those of you who do not know. Git is "A version control tool". Simplified, it is a way to save and load your work when doing anything text based. Including code. If you work with code and do not know GIT… then you REALLY want to learn GIT)
The name GIT does not stand for anything. Its creator, Linus Torvalds have said so. And in start of the the README for the early version of git he writes:
"git" can mean anything, depending on your mood.
- random three-letter combination that is pronounceable, and not actually used by any common UNIX command. The fact that it is a mispronounciation of "get" may or may not be relevant. - stupid. contemptible and despicable. simple. Take your pick from the dictionary of slang. - "global information tracker": you're in a good mood, and it actually works for you. Angels sing, and a light suddenly fills the room. - "goddamn idiotic truckload of sh*t": when it breaks
Source: https://github.com/git/git/blob/e83c5163316f89bfbde7d9ab23ca2e25604af290/README
What is programming and code? (And how to write tutorials )
Easy topic of the day. I have yet to see someone answer this in a good way. It always gets into all sorts of overcomplications and forgets how write good tutorials. You need to know that there are 3 kinds of info you can give
1: How something works 2: Why something works like it does 3: What something is meant to be used for You should try to only do 1 or 2 in a single tutorial, and try NOT to switch between them more than absolutely necessary.
I will explain WHAT and a bit of WHY about programming today. Many programmers, and thus, people who try to teach programming, gets too stuck in HOW (Because it is what we do all day), which is frankly, not important for a higher concept thing programming. So here we go! Programming is autogenerating assembler. ... Ok maybe that needs a bit of flushing out. All code is assembler, or "Anything higher abstraction level than assembly" So to understand that, you need to understand what assembly is. And why 99.9% of you are NOT coding in it. And why(As someone who learned it, and still reads it from time to time at work) you should be very very thankful for that fact. Assembler is the lowest level programming language that exists. And can exist. Because in effect, it is machine language. They fit each-other 1 to 1 A machine language is a list of orders you can tell a CPU. Step by painstaking step. And a CPU can only do 2 things 1: It can save/load numbers 2: It can do simple math on those numbers. Things like add/multiply/divide and subtract EVERYTHING else is humans making up things about what those numbers mean. For example we agreed some 8 bit numbers was ACTUALLY letters. You just looked up what letter any given number represented in a long list. That is called ASCII, and was how computers used to write all text. This business of making up concepts that numbers represented is called encoding. EnCODEing. I am sure you see the connection :) But when writing assembly, you have to keep ALL of that in mind, and look everything up manually. You have to write "104" when you wanted to say "h" Oh, and each assembler language is slightly different, depending on what CPU it was created for. And each CPU have subtle tricks you can use to make it faster. So also keep all of those in mind when programming anything. It is, in other words, a horrible horrible pain to write anything larger than a few instructions. A programming language, is a language humans made up, with the only requirement that it can be translated into assembler. Because then you can write a program called a compiler, to translate your language into assembler, so you can read and write this language instead of having to read and write assembler. Granted, reading and writing C, C++, Java, C#, Kotlin, Python or any of the many MANY others is not the easiest thing, but it beats writing assembly. THAT is what code is. THAT is what programmers write. Language that automates encoding. Some do it by being compiled natively, like C and C++, meaning that you turn your code into assembler instructions to run on a specific machine later. Most likely the same one you wrote the program on. Other like Java, Python or Javascript use something that they call a "interpreter", "virtual machine" or "Browser". These programs can do extra things, but they ALL turn your code into assembler instructions AND runs them. So essentially a compiler that runs the code AS it compiles. But both turns somewhat human readable language, into assembler. All every programmer writes all day, is assembler. And that is sorta fun :)
My place is never cleaner than when I have coding to do that I really do not want to do
It works!*
So I (FINALLY) put the final touches on the software for my robot PROTO! (Listen, I am a software person, not a coming-up-with-names person)

Basically, it is a ESP32 running him. He takes HTTP messages. Either GET odometry, or PUT twist. Both just being a string containing comma separated numbers
Odometry is the robots best guess based on internal sensors where it is (Since PROTO uses stepper motors, which rotates in tiny tiny steps... it is basically counting the steps each motor takes)
Twist is speed, both in x,y and z directions, and speed in angular directions (pitch, roll and yaw). This is used to tell the robot how to move

Now, since PROTO is a robot on two wheels, with a third free-running ball ahead of him, he cannot slide to the side, or go straight up in the air. You can TRY telling him to do that, but he will not understand what you mean. Same with angular movement. PROTO can turn left or right, but he have no clue what you mean if you tell him to bend forward, or roll over.
The software is layered (Which I use a BDD diagram to plan. I love diagrams!)

Basically PROTO gets a twist command and hands that over to the Differential_Movement_Model layer.
The Differential_Movement_Model layer translate that to linear momentum (how much to move forward and backwards) and angular momentum (how much to turn left or right). combines them, and orders each wheel to move so and so fast via the Stepper_Motors layer.
The Stepper_Motors turns the wanted speed, into how many steps each stepper motor will have to do per second, and makes sure that the wanted speed can be achieved by the motors. It also makes sure that the wheels turn the right way, no matter how they are mounted (In PROTO's case, if both wheels turn clockwise, the right wheel is going forward, and the left backwards.). It then sends this steps per second request down to the Peripheral_Hub layer.
The Peripheral_Hub layer is just a hub... as the name implies, it calls the needed driver functions to turn off/on pins, have timers count steps and run a PWM (Pulse-width modulation. It sends pulses of a particular size at a specific frequency) signal to the driver boards.
Layering it, also means it is a lot easer to test a layer. Basically, if I want to test, I change 1 variable in the build files and a mock layer is build underneath whatever layer I want to test.
So if I want to test the Stepper_Motors layer, I have a mock Peripheral_Hub layer, so if there are errors in the Peripheral_Hub layer, these do not show up when I am testing the stepper motor layer.
The HTTP server part is basically a standard ESP32 example server, where I have removed all the HTTP call handlers, and made my own 2 instead. Done done.
So since the software works... of course I am immediately having hardware problems. The stepper motors are not NEARLY as strong as they need to be... have to figure something out... maybe they are not getting the power they need... or I need smaller wheels... or I will have to buy a gearbox to make them slower but stronger... in which case I should proberbly also fix the freaking cannot-change-the-micro-stepping problem with the driver boards, since otherwise PROTO will go from a max speed of 0.3 meters per second, to most likely 0.06 meters per second which... is... a bit slow...
But software works! And PROTO can happily move his wheels and pretend he is driving somewhere when on his maintenance stand (Yes. it LOOKS like 2 empty cardboard boxes, but I am telling you it is a maintenance stand... since it sounds a lot better :p )
I have gone over everything really quickly in this post... if someone wants me to cover a part of PROTO, just comment which one, and I will most likely do it (I have lost all sense of which parts of this project is interesting to people who are not doing the project)
Oh this is GREAT. I am a big fan of diagrams to get a grasp of what is happening with code (Learning to make UML diagrams was the best supporting skill for learning and communicating code for me) :D People learning git for the first time often have trouble with what the local and remote repository is, what the difference is and which is which. Also, first and most important git command everyone should learn: git status It tells you what git thinks is where. It is THE command for starting to use, and learn, git.

Git cheat sheet guys 😉
Git is a powerful version control system widely used in software development to manage source code and track changes. Whether you're a beginner or an experienced developer, having a handy cheat sheet can be incredibly useful to quickly reference common Git commands and workflows. Here's a comprehensive Git cheat sheet to help you navigate through various Git operations:
🌐 www.certhippo.com 📧 info@certhippo.com 📱 https://wa.me/+13029562015 ☎️ +1 302 956 2015
What to do when you spot a broken website
I am a very firm believer in either sticking to your principles or update them.
So when I got this error while I tried to search for C/C++ on my national job portal:

My first thought was "Huh, that is sorta funny" (especially since the code to show me the email address to report this error to was ALSO broken... meaning that whoever made the code that should run if the website broke... never tested it). And then I realized what I was looking at.
And at that point I think I had a ethical duty to notify people to get this fixed. FAST. Why?
It comes under "You are responsible for your choices". With it being understood that doing nothing is also a choice, and that taking a job where you work for, and help a company with doing evil is NOT a choice, if that is the only job you could get (IE, you did not have the power/money/mental health/time to make a choice)
It is now fixed*, so I wanted to make this post for all in the little codeblr community doing any front-end work. Web or not. With 3 lessons to learn from this.
First thing to get from this: "Everyone makes mistakes". This is one of the reason good code is not code without errors. It is code where it is easy to make changes and fix errors. You then try to find as many errors as you can with code reviews, automated testing, having a work environment that does not punish human errors( which encourages people to HIDE errors ) and so on.
Second thing: "Sanitize your user input. Always". Write code that assumes that every single user wants nothing more than to break your code and exploit its vulnerabilities.
This had NOT been done here. This error shows that characters in the string that was made from my search terms, was being run as code. As in, I, or anyone else, could run code in the middle of this javascript code. Meaning it is possible that someone could write code as part of their search that would make the javascript code do... whatever they wanted to. Including deleting the entire backend database. Or steal the info. This is why you ALWAYS sanitize your user input. Basically encode all potentially dangerous characters as something else while working on them. There are libraries like validator.js and express-validator that will do it for you, if you use javascript.
And the third thing. "Do NOT investigate further" . As soon as you confirm that your user input gets treated as code, you contact whoever is running it. If they do not take the threat seriously and it is still there after a week or two, contact established press with this info. You may read about so called grey hat hackers, who unlike black hat hackers(who is people wishing to do harm) or white hat hackers(Who are hired to try to break into a companies software to test it), are trying to find security flaws with good intentions, but are unaffiliated with whoevers code they are trying to break into. In an ideal world, doing that, and then contacting the company, SHOULD result in the company thanking them . But often it also leads to the company suing. And winning. Since breaking in to show that it is possible, is technically still breaking in. So do NOT start testing what you are able to do with the exploit you found. Report it to them, and check a weeks time later if it is fixed. If it keeps being vulnerable, contact the press. The site fixed this error after half a week. But they did it, not by encoding the dangerous characters into something else, but to simply remove them all from the user input string. Meaning that I still cannot search for "C++". Now I just get any job that contains the letter "C"... I mean... it is better... So if you take user input, and it does not brick your code in dangerous ways. You are doing better than whoever coded this for the Danish State :p
Going to make a "Getting started with GIT" Post
(This is my getting the "why are you making that post" out of the way, so that the posts with the actual information does not get polluted by it. And also polling people on what they find confusing about GIT so I can target that a bit better) So I re-blogged a post with a really nice GIT diagram, showing what commands sends what where. And I noticed 3 things in the replies and reblog. 1: A lot of people seem to be intimidated by the perceived complexity of GIT. That is fair. But I promise, while HOW it works is complicated, using it is not. 2: Many have it on a TODO list for after they learn to code. Which is... backwards. It would be like waiting with learning how to use a keyboard until after you have become a good writer. Trust me, learning GIT as one of the first things will make it EASIER to learn to code. 3: Several people suggested that GIT is overcomplicated. That is... simply not true. It is one of the old school pieces of software (Meaning it does 1 thing, is open-source, free and is impossible to monetize). It does something very very complicated in the simplest way possible. I think people simply do not understand how complicated the problem GIT solves is. I am not saying "People are dumb" (I think... anyone thinking that is fundamentally missing something in how the world works.), I am saying "People seem to be either misinformed or not informed". And that I can help with!
I WILL make a "Getting started with GIT" Post, but if people want an easy explanation for something more, then I will also make posts for those later... Or maybe they fit in as part of a getting started post. We shall see
Honestly I have nothing to add. This is just 100% correct and well explained.
Why Not Write Cryptography
I learned Python in high school in 2003. This was unusual at the time. We were part of a pilot project, testing new teaching materials. The official syllabus still expected us to use PASCAL. In order to satisfy the requirements, we had to learn PASCAL too, after Python. I don't know if PASCAL is still standard.
Some of the early Python programming lessons focused on cryptography. We didn't really learn anything about cryptography itself then, it was all just toy problems to demonstrate basic programming concepts like loops and recursion. Beginners can easily implement some old, outdated ciphers like Caesar, Vigenère, arbitrary 26-letter substitutions, transpositions, and so on.
The Vigenère cipher will be important. It goes like this: First, in order to work with letters, we assign numbers from 0 to 25 to the 26 letters of the alphabet, so A is 0, B is 1, C is 2 and so on. In the programs we wrote, we had to strip out all punctuation and spaces, write everything in uppercase and use the standard transliteration rules for Ä, Ö, Ü, and ß. That's just the encoding part. Now comes the encryption part. For every letter in the plain text, we add the next letter from the key, modulo 26, round robin style. The key is repeated after we get tot he end. Encrypting "HELLOWORLD" with the key "ABC" yields ["H"+"A", "E"+"B", "L"+"C", "L"+"A", "O"+"B", "W"+"C", "O"+"A", "R"+"B", "L"+"C", "D"+"A"], or "HFNLPYOLND". If this short example didn't click for you, you can look it up on Wikipedia and blame me for explaining it badly.
Then our teacher left in the middle of the school year, and a different one took over. He was unfamiliar with encryption algorithms. He took us through some of the exercises about breaking the Caesar cipher with statistics. Then he proclaimed, based on some back-of-the-envelope calculations, that a Vigenère cipher with a long enough key, with the length unknown to the attacker, is "basically uncrackable". You can't brute-force a 20-letter key, and there are no significant statistical patterns.
I told him this wasn't true. If you re-use a Vigenère key, it's like re-using a one time pad key. At the time I just had read the first chapters of Bruce Schneier's "Applied Cryptography", and some pop history books about cold war spy stuff. I knew about the problem with re-using a one-time pad. A one time pad is the same as if your Vigenère key is as long as the message, so there is no way to make any inferences from one letter of the encrypted message to another letter of the plain text. This is mathematically proven to be completely uncrackable, as long as you use the key only one time, hence the name. Re-use of one-time pads actually happened during the cold war. Spy agencies communicated through number stations and one-time pads, but at some point, the Soviets either killed some of their cryptographers in a purge, or they messed up their book-keeping, and they re-used some of their keys. The Americans could decrypt the messages.
Here is how: If you have message $A$ and message $B$, and you re-use the key $K$, then an attacker can take the encrypted messages $A+K$ and $B+K$, and subtract them. That creates $(A+K) - (B+K) = A - B + K - K = A - B$. If you re-use a one-time pad, the attacker can just filter the key out and calculate the difference between two plaintexts.
My teacher didn't know that. He had done a quick back-of-the-envelope calculation about the time it would take to brute-force a 20 letter key, and the likelihood of accidentally arriving at something that would resemble the distribution of letters in the German language. In his mind, a 20 letter key or longer was impossible to crack. At the time, I wouldn't have known how to calculate that probability.
When I challenged his assertion that it would be "uncrackable", he created two messages that were written in German, and pasted them into the program we had been using in class, with a randomly generated key of undisclosed length. He gave me the encrypted output.
Instead of brute-forcing keys, I decided to apply what I knew about re-using one time pads. I wrote a program that takes some of the most common German words, and added them to sections of $(A-B)$. If a word was equal to a section of $B$, then this would generate a section of $A$. Then I used a large spellchecking dictionary to see if the section of $A$ generated by guessing a section of $B$ contained any valid German words. If yes, it would print the guessed word in $B$, the section of $A$, and the corresponding section of the key. There was only a little bit of key material that was common to multiple results, but that was enough to establish how long they key was. From there, I modified my program so that I could interactively try to guess words and it would decrypt the rest of the text based on my guess. The messages were two articles from the local newspaper.
When I showed the decrypted messages to my teacher the next week, got annoyed, and accused me of cheating. Had I installed a keylogger on his machine? Had I rigged his encryption program to leak key material? Had I exploited the old Python random number generator that isn't really random enough for cryptography (but good enough for games and simulations)?
Then I explained my approach. My teacher insisted that this solution didn't count, because it relied on guessing words. It would never have worked on random numeric data. I was just lucky that the messages were written in a language I speak. I could have cheated by using a search engine to find the newspaper articles on the web.
Now the lesson you should take away from this is not that I am smart and teachers are sore losers.
Lesson one: Everybody can build an encryption scheme or security system that he himself can't defeat. That doesn't mean others can't defeat it. You can also create an secret alphabet to protect your teenage diary from your kid sister. It's not practical to use that as an encryption scheme for banking. Something that works for your diary will in all likelihood be inappropriate for online banking, never mind state secrets. You never know if a teenage diary won't be stolen by a determined thief who thinks it holds the secret to a Bitcoin wallet passphrase, or if someone is re-using his banking password in your online game.
Lesson two: When you build a security system, you often accidentally design around an "intended attack". If you build a lock to be especially pick-proof, a burglar can still kick in the door, or break a window. Or maybe a new variation of the old "slide a piece of paper under the door and push the key through" trick works. Non-security experts are especially susceptible to this. Experts in one domain are often blind to attacks/exploits that make use of a different domain. It's like the physicist who saw a magic show and thought it must be powerful magnets at work, when it was actually invisible ropes.
Lesson three: Sometimes a real world problem is a great toy problem, but the easy and didactic toy solution is a really bad real world solution. Encryption was a fun way to teach programming, not a good way to teach encryption. There are many problems like that, like 3D rendering, Chess AI, and neural networks, where the real-world solution is not just more sophisticated than the toy solution, but a completely different architecture with completely different data structures. My own interactive codebreaking program did not work like modern approaches works either.
Lesson four: Don't roll your own cryptography. Don't even implement a known encryption algorithm. Use a cryptography library. Chances are you are not Bruce Schneier or Dan J Bernstein. It's harder than you thought. Unless you are doing a toy programming project to teach programming, it's not a good idea. If you don't take this advice to heart, a teenager with something to prove, somebody much less knowledgeable but with more time on his hands, might cause you trouble.
If you do ANY C++, You need to watch Jason Turners!
Oh my god, I just realized I have never plugged Jason Turners youtube channel on this blog!!! This must immediately be remedied!

Not only is this man VERY easy to listen to, and give great examples of everything he talks about, from super basic begginer concepts and up to stuff about how C++ compilers decide what template classes to implement for any given use of the function. Can only be recommended. It is FACINATING how all the tiny details of C++ clicks and pops, and make that glorus optimized, and smooth machine that is C++ run. Love it